Machine Learning as a Service: How Data Science Is Hitting the Masses
Source: Laura Dambrosio
Machine learning is an enigma to most. For decades it’s a been a field dominated by scientists and the few organizations with enough computing power to run complex algorithms against huge datasets. But now the world of machine learning and predictive analytics is opening up to developers and companies of all sizes, with machine learning (ML) providers offering their products through a subscription-based model or open sourcing some of their technology.
These new ML providers comprise a predictive analytics industry worth anything between $5-10 billion, depending on the source. There’s something for everyone: a developer who wants to build predictive analytics into their application, a customer success team that needs to know which accounts are likely to churn, a data scientist looking to run models on faster and cheaper infrastructure. These people can now shop for the machine learning product of their choice—a farfetched idea just several years ago.
The Perfect Convergence of Ability and Demand
In just the last few years, over 90% of all the data in the world was created. NoSQL databases got popular, SQL got faster, and projects like Apache Spark did wonders for the speed and performance of large-scale data processing. Suddenly we had mountains of data and a fast, affordable means of drawing insight from it.
ML providers are taking advantage of that. Some have been in the industry for years—take Apigee‘s CTO, Anant Jhingran. Jhingran was VP and CTO for IBM’s Information Management Division, working closely on groundbreaking data projects like Watson. Today his team at Apigee uses predictive technology to help developers build apps that can learn from the constant stream of user data flowing through APIs. They have customers in almost every major industry using their predictive technology to do things like detect fraud or show personalized shopping recommendations to end users.
“It’s the era of cheap computing and cheap memory.”
H2O.ai‘s Vinod Iyengar is another player in ML market. He’s Director of Marketing for the open source machine learning company that was first venture-backed in 2013. Iyengar sees a high demand for predictive in many industries, explaining that “there’s a huge need to be filled”.
“The amount of data available has shot up exponentially”, Iyengar says. “Enormous amounts are being collected and stored every day thanks to cheaper costs of storage and cloud computing. Once that happens, you can’t use your old algorithms on these large datasets. All of the different platforms, Hadoop, Spark, are starting to chip away at this problem. It’s the era of cheap computing and cheap memory.”
H2O is entirely open source. It lets developers use its technology stack to process large amounts of data and run it through H2O’s algorithms to make predictions. Like the many other open source projects in the field, it’s completely free if you only use the community resources. This flexibility opens up opportunities for companies of all sizes—from those experimenting to those ready to make a real investment in machine learning.
How APIs and Open Source are Democratizing Data
Two things pose a threat to actually putting machine learning to work: poor data quality and lack of data integration. The improvement of APIs and the trend of open sourcing some or all of the technology stack can abolish those threats.
Jhingran, whose core business is in developing and managing better APIs, believes that the real power for digital transformation lies in the apps. “Today’s apps need to learn and adapt”, he says, “and to do that there needs to be a consistent data stream of signals about the behaviors and actions of the end users from all channels of engagement. You can use the data to generate really deep insights with machine learning, then feed the results back into the apps to make improvements.”
This is important because before APIs were this intelligent or ubiquitous, a company only had access to a small portion of user data that happened on its own website or platform. They had to make guesses on what was working without information from data sources like email campaigns, iOS apps, payment platforms, or any number of places where users were having important interactions. And as Jhingran summarizes perfectly, “There’s no way you can run a machine learning algorithm on such limited inputs.”
While APIs are connecting data from many sources and putting it to work, the open source movement is giving anyone the chance to use the collective knowledge from data scientists and developers who have been working in this field. H2O’s platform and algorithms are all open source, Iyengar explains. “All of H2O is exposed via a REST API. Data scientists and developers can choose the language and environment that works best for them. If our customers need more guidance, that’s another level of support that we provide.”
There are tons of other open source projects on github that developers can use to incorporate machine learning into their applications. And companies like Google are releasing lower-level libraries like Tensorflow, which can be used in conjunction with others to perfectly match the level of sophistication a developer or data scientist is looking for. Even the less-technical user can take advantage of a service like Amazon Machine Learning, which provides a simple UI for non-developers.
Now the crossroads: If APIs and the open source community are making machine learning technology accessible to all, why not hire data scientists of your own and get to work?
Why Not Just Hire Your Own Data Scientists?
As machine learning gets more popular as a service, companies will have to decide at what level they want to be involved. “Having a scientist in house or not is a decision most companies will have to make”, Jhingran predicts. “The power of predictive is so high. But wanting to do it and being able to do it are two different things. Some companies will choose a platform like ours to manage the entire cycle of data intelligence instead of trying to do it in-house, and that will let them focus on developing and powering their applications.”
Iyengar agrees. “There are only so many PhDs”, he says, “and while there’s huge hype for data scientists right now, there’s a limited number of potential hires out there. Right now there is still a lot of manual decision-making involved in machine learning, and you should either begin your search now or find a partner you trust.”
“There are only so many PhDs.”
Like many in the predictive market, Iyengar believes it’s good to do some of the leg work in-house if you’re going to adopt predictive. But there’s a reason his company and others like it are hired to manage the data. It’s not easy to do it without the talent, infrastructure, and scalability that ML providers have found.
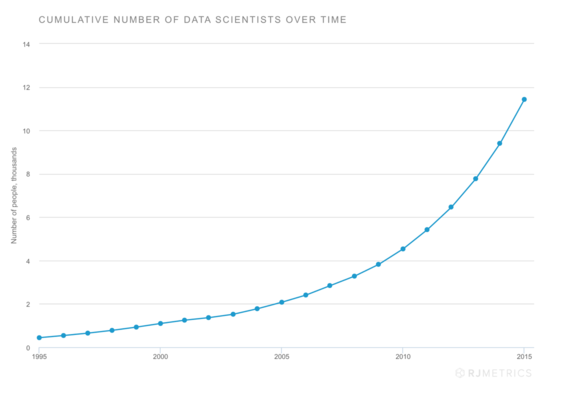
Data scientists are growing in number, but only in the tens of thousands...
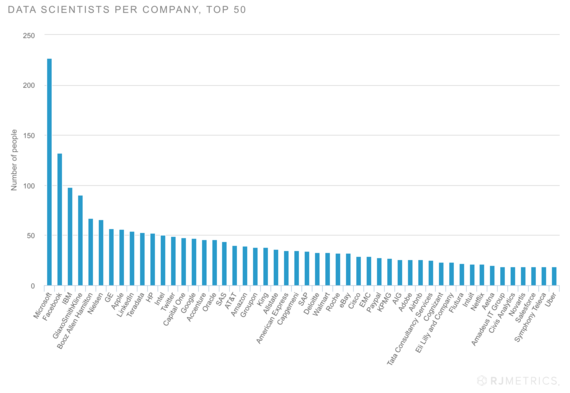
...and thousands are going to work for the top companies. There may not be enough to go around.
Navigating a Booming Market
If you decide to shop around for good machine learning provider, you’ll need to ask the right questions. You can get oriented by checking out Zachary Chase Lipton’s series of articles that compare some of the major vendors.
A good vendor should be able to explain both how they manage data and how they solve your specific business problem. Iyengar suggests asking some questions to see if a predictive company will be a good fit: “Ask a [ML provider] how they handle unclean data. Their answer will show you how well they know their work. You can also ask about the variety of algorithms they use, since they should have a good variety of fairly robust algorithms. They should be comfortable explaining how they deploy a model structure, what their web stack looks like, and how that will work with customer architecture.”
Jhingran expects the main differentiator among competing ML providers will be on how they apply the technology to improve applications and business strategy. “It’s astounding how the art of data science has improved over a short time thanks to open source. Over time, the competitive position you have from your own ‘secret sauce’ algorithms will dwindle—it will be all about how easily the models can be used by both scientists and developers to impact the organization.”
Machine learning and predictive techniques impact every major industry. It may soon be an essential line item in most companies’ budgets. But here’s a dirty secret: no matter how good the algorithm, no matter how good the scientist, the models can’t perform magic.
“No data in, no science out,” jokes Jhingran. Whoever has the best sense for choosing, organizing, and acting on the torrent of incoming customer data might end up with the best long-term outlook in a market that’s just getting started.
| }
|